
Mouser: La evolución del control de audio y voz en los dispositivos electrónicos
La voz es una herramienta eficaz para que la gente exprese sus ideas y deseos. Antes de la era industrial, los seres humanos descubrieron que era posible entrenar a los animales para que reconocieran algunas instrucciones básicas y respondieran a ellas a fin de llevar a cabo alguna tarea.

asistente robótico controlado por voz.
El siguiente paso lógico era desarrollar un método para comunicarnos y transmitir instrucciones por voz a las máquinas. El uso de voz y audio como interfaz de control para dispositivos electrónicos ha aumentado su popularidad en los últimos años, y está evolucionando para cumplir con las expectativas de los usuarios y con los requisitos de las nuevas aplicaciones.
En este artículo, hablaremos sobre las ventajas de la voz y el audio como elementos para controlar máquinas y equipos electrónicos, y repasaremos los métodos existentes para implementarlos. Además, veremos que estas interfaces de control ya se pueden integrar en dispositivos sin conexión, y analizaremos qué se puede hacer para mejorar considerablemente la experiencia de audio que ofrecen.
El uso de la voz para controlar dispositivos electrónicos
El uso de la voz para interactuar con las máquinas posee algunas ventajas evidentes:
- Para los seres humanos, la voz es un método de comunicación intuitivo que simplifica la transmisión de instrucciones.
- La voz se puede utilizar aunque la persona tenga las manos y los ojos ocupados en otras cosas. Además, el control por voz simultáneo resulta muy práctico, ya que, en algunos casos, como a la hora de conducir un vehículo, usar las manos para controlar otro dispositivo es ilegal.
- La voz es un método eficaz que permite controlar máquinas capaces de escuchar y responder sin necesidad de comandos complejos.
- En varios dispositivos, al integrar la voz podemos eliminar las pantallas táctiles, algo especialmente útil para equipos ubicados en lugares remotos o portátiles y de batería, ya que, en estas aplicaciones, la reducción del tamaño y del consumo de potencia suelen ser elementos importantes y complejos. Además, la eliminación de la función táctil también resulta más higiénica en aplicaciones con varios usuarios.
- Como se aprecia en la imagen 1, esto puede aportar control a personas con algún tipo de discapacidad que les impida usar las funciones táctiles. La comunicación por voz con máquinas se puede emplear para llevar a cabo tareas como abrir puertas o transmitir a distancia información actualizada sobre el estado de salud de una persona.
El frontal de audio (AFE) de un dispositivo controlado por voz incluye una matriz de micrófonos y bloques de procesamiento de señal. El AFE procesa la señal desde una matriz multicanal para eliminar las interferencias causadas por el ruido de fondo o por la propia reproducción del dispositivo. Después, esta señal se envía a un motor de detección de palabra de activación que reconoce términos preprogramados en el dispositivo, como «Alexa» o «Ok, Google». Se utilizan distintos algoritmos de procesamiento de señal para eliminar las interferencias. Algunos de los elementos de una solución de control por voz incluyen:
Una matriz de micrófonos: los sistemas de activación por voz necesitan uno o más micrófonos para captar la señal de control de audio. El tamaño, el coste, el rendimiento y la resistencia son los elementos principales que debemos tener en cuenta al escoger una matriz de micrófonos. La combinación de distintas señales desde una de estas matrices contribuye a mejorar la relación señal-ruido (SNR) en la cadena de señal de audio.
Un detector de dirección de llegada (DoA): se utiliza para determinar la posición del usuario con respecto al dispositivo controlado, a fin de que el micrófono pueda dirigir un haz en la dirección de la voz.
Un formador de haces: este elemento acepta sonidos del DoA y rechaza los que provienen de otras direcciones. Su rendimiento depende de la geometría y de la SNR de la matriz de micrófonos, así como del ancho del haz y del nivel de ruido de fondo.
Un cancelador de eco acústico (AEC): se encarga de rechazar la señal de reproducción del propio altavoz del dispositivo (por ejemplo, si este está reproduciendo música) a fin de captar con claridad las instrucciones por voz del usuario.
Un cancelador de interferencias adaptativo (AIC): cancela el ruido externo que proviene de otras fuentes de sonido y que es difícil de cancelar con un formador de haces tradicional. Por ejemplo, el ruido de alto nivel generado por otros equipos.
Un detector de palabra de activación: la señal de voz procesada desde el AFE se compara con una biblioteca de palabras de activación, como «Hey Google», mediante un algoritmo de detección que forma parte de un modelo de aprendizaje automático. Los modelos más grandes son más precisos. Por ejemplo, un modelo entrenado de 1 MB será más preciso que un modelo de 64 kB, pero requiere más trabajo por parte del procesador. A fin de detectar de forma precisa la palabra de activación y reducir el número de alarmas falsas, es necesario emplear modelos grandes.
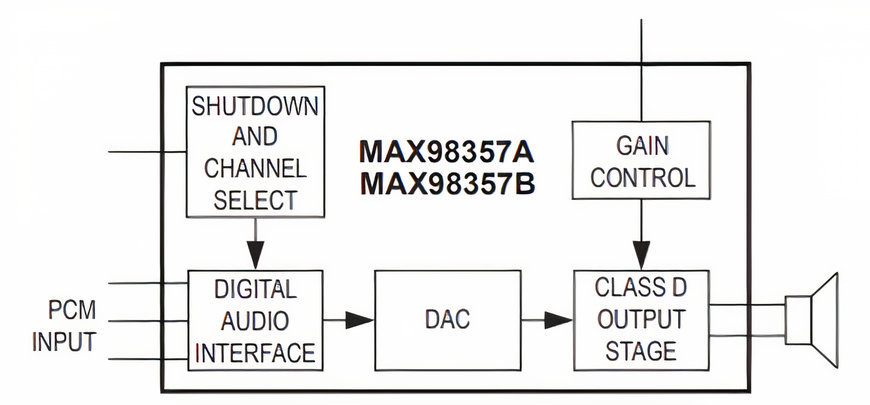
diagrama de bloques simplificado de los amplificadores de audio de clase D de Maxim Integrated
Amplificadores de audio de clase D
En estas interfaces de control, la parte encargada del procesamiento de voz ha experimentado un gran desarrollo. En la actualidad, incluso los dispositivos de bajo coste pueden ofrecer un reconocimiento de voz preciso. Sin embargo, los trabajos de desarrollo han pasado por alto, hasta cierto grado, el elemento de audio y, como resultado, la calidad del sonido generado por muchos de los primeros altavoces inteligentes y otros dispositivos con audio del Internet de las Cosas (IdC) era inferior al de los equipos de audio de calidad.
Como el control por voz era una novedad, es posible que existiese la percepción de que eso eclipsaría de algún modo tal defecto. Sin embargo, a medida que los dispositivos inteligentes han ido adquiriendo mayor implantación, los consumidores también han aumentado sus expectativas sobre la experiencia de sonido que ofrecen. Los amplificadores de audio AB tradicionales tienen un nivel bajo de eficacia, así que no son una solución práctica para los dispositivos IdC.
Sin embargo, los fabricantes de chips acaban de presentar una nueva gama de amplificadores de audio de clase D que supone una mejora considerable con respecto a los dispositivos anteriores. Muchos se han diseñado especialmente para lograr un audio de alta calidad en dispositivos IdC y de tecnología inteligente.
El TAS2770, un amplificador de audio de 15 W de entrada de Texas Instruments, aumenta el volumen y la calidad del audio y logra capturar mejor la voz, lo que permite utilizar de un modo más sencillo y natural los dispositivos controlados por voz. Se trata del primer frontal de audio capaz de combinar una entrada de micrófono digital con un potente amplificador con detección de tensión e intensidad.
Gracias a esto, es posible capturar la voz y el ruido ambiental a fin de eliminar el eco o reducir el ruido en aplicaciones por voz. En Maxim Integrated (ahora parte de Analog Devices), han diseñado sus amplificadores de clase D MAX98357 y MAX98358 con una eficacia del 92 % y un rendimiento de audio de clase AB de 3,2 W. En la imagen 2se puede observar un sencillo diagrama de bloques de estos amplificadores. El PAM8106 de Diodes Incorporated tiene un bajo consumo de potencia, así que es una buena opción para dispositivos con baterías de plomo-ácido de 1,5 V o con baterías de iones de litio de 3,5 V. Alcanza una eficacia del 92 % y se puede utilizar en un diseño compacto, ya que no precisa radiadores de gran volumen.

solución de control por voz sin conexión SLN-LOCAL2-IOT de NXP
Control por voz sin conexión
Ya hay soluciones en la nube disponibles, como Alexa de Amazon o Google Assistant, para dispositivos con una conexión estable a Internet, pero cuando la conectividad es baja o inexistente, es mejor optar por el control por voz sin conexión. Por ejemplo, si un producto debe responder a instrucciones sencillas, como ir, parar, reiniciar, etc. (algo conocido como identificación de palabras clave), lo normal es que el procesamiento se lleve a cabo en el propio dispositivo.
Se puede implementar un sistema sencillo de instrucciones por palabras clave con un microcontrolador integrado y de bajo coste, como la solución con microcontrolador EdgeReady de NXP para el control por voz local y sin conexión. Se trata de un sistema que emplea el microcontrolador crossover i.MX RT y los desarrolladores pueden usarlo para añadir rápidamente control por voz a sus productos. La solución con el i.MX RT106S de NXP incluye el kit de desarrollo SLN-LOCAL2-IOT, que aparece en la imagen 3.
Cuenta con software totalmente integrado, que se ejecuta en FreeRTOS, y viene con un kit de desarrollo de software (SDK) para lograr rápidamente una prueba de diseño. Con esta solución, los fabricantes pueden añadir fácilmente control por voz en hogares, electrodomésticos, edificios y productos industriales inteligentes sin necesidad de wifi o conexión a la nube. El control por voz sin conexión también contribuye a solucionar los problemas de privacidad de muchos consumidores, que temen que sus sistemas sean vulnerables a intrusos en línea. El kit dispone también de una herramienta de Windows™ para crear modelos de habla para más de cien instrucciones personalizadas y un gran número de palabras de activación a partir de la entrada de texto en más de cuarenta idiomas.
Conclusión
En un gran número de dispositivos inteligentes, la voz y el audio se están convirtiendo en la interfaz más utilizada, pero también son especialmente útiles en dispositivos portátiles y de bajo consumo para el IdC, ya que eliminan la necesidad de pantallas digitales de alto consumo. Muchos de los primeros sistemas tenían una calidad de audio baja y solo se podían usar con una solución conectada a la nube.
Sin embargo, actualmente existe una nueva generación de amplificadores de audio de clase D de gran eficacia con la que los fabricantes ofrecen a los consumidores una experiencia de audio de alta calidad. Además, han aparecido soluciones con las que es posible controlar dispositivos que tengan una conectividad a Internet baja o inexistente. Estas innovaciones demuestran que esta tecnología se adapta para satisfacer las demandas que vayan surgiendo a medida que la gente se acostumbre a emplear esta interfaz de control, algo que probablemente siga en aumento.
www.mouser.com
