
electronica-news.es
17
'22
Written on Modified on
Mouser News
No mueva datos, mueva el algoritmo: cómo implementar el almacenamiento computacional
El uso de redes neuronales de aprendizaje automático sigue creciendo, y eso significa procesar un volumen de datos masivo. Desde el punto de vista informático, la tendencia siempre ha sido mover los datos al lugar en el que el algoritmo los vaya a procesar.

Sin embargo, los enormes conjuntos de datos de hasta 1 PB se han convertido rápidamente en algo normal. Como el algoritmo encargado del procesamiento quizá solo funcione con decenas de megabytes, el concepto de procesar los datos cerca del dispositivo de almacenamiento está adquiriendo mucha importancia. En este artículo, hablaremos de los conceptos y la arquitectura que hay detrás del almacenamiento computacional; veremos también que los procesadores de almacenamiento computacional (CSP) ofrecen ventajas en rendimiento y aceleración de hardware para una gran variedad de tareas de gran carga computacional, y sin imponer un coste de carga en el procesador del host.
Y subiendo: los conjuntos de datos no pararán de crecer
En los últimos años, hemos visto un aumento espectacular en el uso de las redes neuronales, sobre todo en aplicaciones industriales, de seguridad, de automoción y para el consumidor. Algunos algoritmos, como los empleados en los sensores periféricos del IdC, ocupan muy poco espacio de código y procesan pocos datos. El uso de algoritmos de aprendizaje automático en la periferia está creciendo exponencialmente, gracias al progreso de las funciones en los microcontroladores integrados de baja potencia y de la capacidad del motor de las redes neuronales. Las aplicaciones industriales y para la automoción se centran principalmente en el procesamiento de la visión para detectar objetos con una red neuronal específica, llamada red neuronal convolucional.
Por ejemplo, en un procesamiento sencillo de visión industrial, se puede detectar si una etiqueta se ha adherido correctamente a una botella en una línea de alta velocidad. Un ejemplo más complejo sería el de ordenar frutas, por ejemplo, manzanas, según el tamaño, el estado y el tipo. Las aplicaciones de procesamiento de visión en tiempo real en el sector de la automoción amplían aún más el uso de los algoritmos de redes neuronales, ya que requieren la identificación y clasificación de múltiples objetos. Las redes neuronales también se usan de manera generalizada en la investigación científica; por ejemplo, para analizar los datos recopilados en satélites de detección remota y en los conjuntos globales de sensores de terremotos se procesan conjuntos de datos enormes.
En la mayoría de aplicaciones de aprendizaje automático, cada vez es más necesario predecir las clasificaciones y observaciones con un mayor nivel de probabilidad. Para lograrlo, necesitamos conjuntos de datos más grandes para la formación, lo que, a su vez, requiere el movimiento, el procesamiento y el almacenaje constante de conjuntos de datos de hasta 1 PB.
Almacenamiento computacional
Los dispositivos de almacenamiento flash NAND se han popularizado notoriamente en la última década. Al principio, solo se usaban en aplicaciones de almacenamiento de gama alta, pero ahora las memorias NAND para discos de estado sólido están por todas partes, y han reemplazado a los discos magnéticos tradicionales en la mayoría de ordenadores y portátiles. Este estilo de almacenaje, junto con la llegada del protocolo de memoria exprés no volátil (NVMe) y la evolución de la velocidad de los datos en la conectividad PCIe, han abierto el camino a un diseño distinto en el almacenamiento y los recursos de computación. Las tecnologías de almacenamiento NVMe se caracterizan por un mayor ancho de banda, una baja latencia y mayores densidades de almacenamiento.
En una arquitectura computacional clásica (imagen 1), los datos se envían entre los planos de almacenamiento y de computación. Los recursos computacionales se utilizan para mover y procesar los datos, comprimir/descomprimir y muchas otras tareas relacionadas con el sistema. Por lo tanto, este método tradicional ejerce una importante carga en los recursos computacionales disponibles.
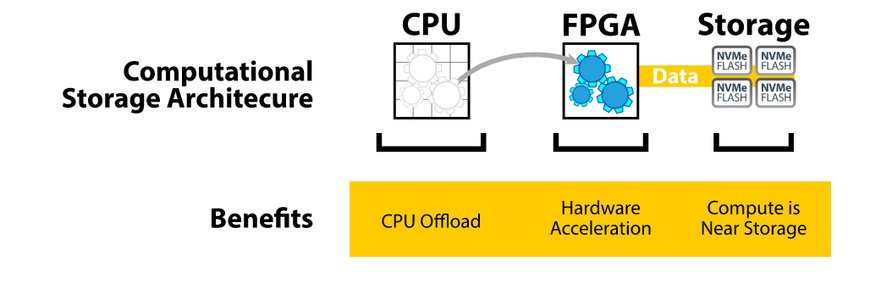
Imagen 2: un planteamiento de arquitectura de almacenamiento computacional (fuente: BittWare).
Un método de computación más eficiente consiste en poner en marcha una arquitectura de almacenamiento computacional (imagen 2). Este método libera las tareas computacionales y las lleva a un acelerador de hardware, normalmente, un FPGA. El acelerador se conecta a un almacenamiento flash NVMe coubicado. Como los datos están cerca del lugar en el que se lleva a cabo la computación, ya no es necesario que la CPU transfiera los datos. La FPGA forma un procesador de almacenamiento computacional o CSP (ver imagen 3), y todas las tareas de alto nivel de computación —como la compresión, la codificación o la inferencia de redes neuronales— se pueden sacar de la CPU.
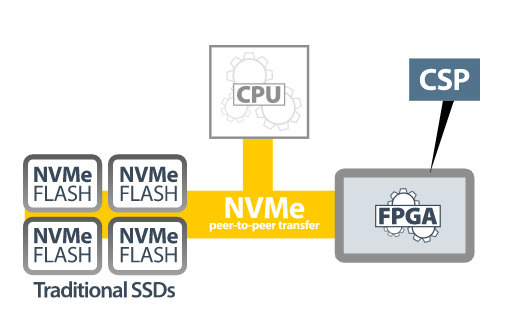
Imagen 3: procesador de almacenamiento computacional o CSP (fuente: BittWare).
El procesador de almacenamiento computacional en FPGA BittWare IA-220-U2
El IA-220-U2 de BittWare (¿enlace Mouser?) es un ejemplo de procesador de almacenamiento computacional. Está compuesto de un FPGA Intel Agilex con hasta 1,4 millones de elementos lógicos, memoria de hasta 16 GB DDR4 y cuatro interfaces PCIe Gen4. La SDRAM DDR4 puede llegar a tasas de transferencia de hasta 2400 MT/s. El encapsulado cumple con el estándar SFF-8639, mide 2,5 pulgadas y tiene un factor de forma U.2 y un disipador de calor refrigerado por convección; el IA-220-U2 está diseñado para formar parte de un conjunto de almacenamiento U.2 NVMe (ver la imagen 4).

Imagen 4: el BittWare IA220-U2 se ha diseñado para poder integrarse en un encapsulado de almacenamiento U.2 estándar (fuente: BittWare).
Permite el cambio en caliente y suele requerir hasta 20 W de la fuente de alimentación U.2 del host. Para facilitar la implantación del IA-220-U2 de BittWare en centros de datos y en la informática corporativa, dispone de un controlador SMBus integrado (de conformidad con el estándar NVMe-MI), una función de control flash FPGA SMBus y acceso SMBus para los sensores integrados de supervisión de temperatura y tensión.
En la imagen 5 se puede ver el diagrama de funcionamiento del IA-220-U2 de BittWare con todas las funciones principales.
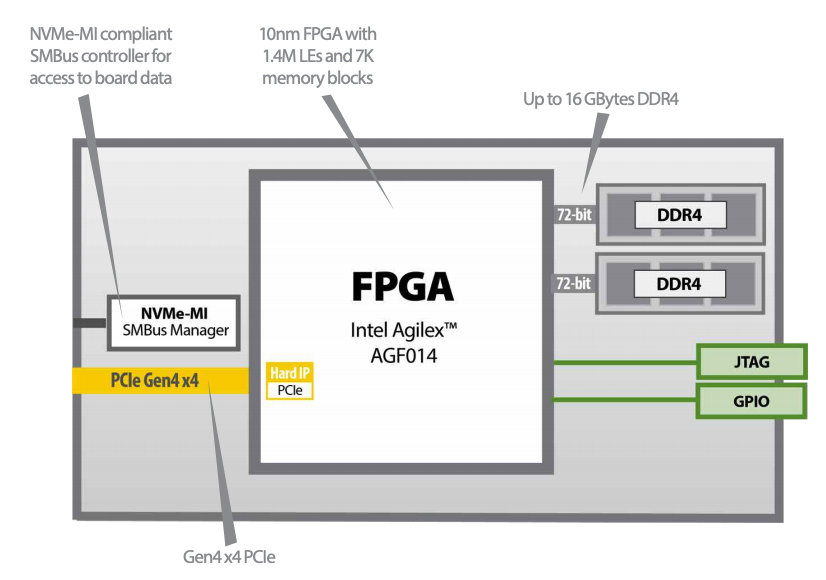
Imagen 5: diagrama de funcionamiento del IA-220-U2 de BittWare (fuente: BittWare).
El IA-220-U2 se ha diseñado para una amplia gama de tareas de aceleración y aplicación de gran volumen, desde la inferencia, la compresión, la codificación y el hashing de algoritmos hasta la búsqueda de imágenes, la clasificación de bases de datos y la desduplicación.
La implementación del CSP con el IA-220-U2 de BittWare
Los clientes pueden programar de forma personalizada el BittWare IA-220-U2 según lo que necesite su aplicación, pero también se puede vender con la estructura NoLoad IP de Eideticom preconfigurada.
BittWare ofrece un kit de desarrollo de software que incluye controladores PCIe, funciones de monitorización de placa y bibliotecas de placa para facilitar el desarrollo personalizado. Además, la opción del desarrollo de aplicaciones FPGA está disponible con el Quartus Prime Pro de Intel y con flujos de diseño y cadenas de herramientas de síntesis de alto nivel.
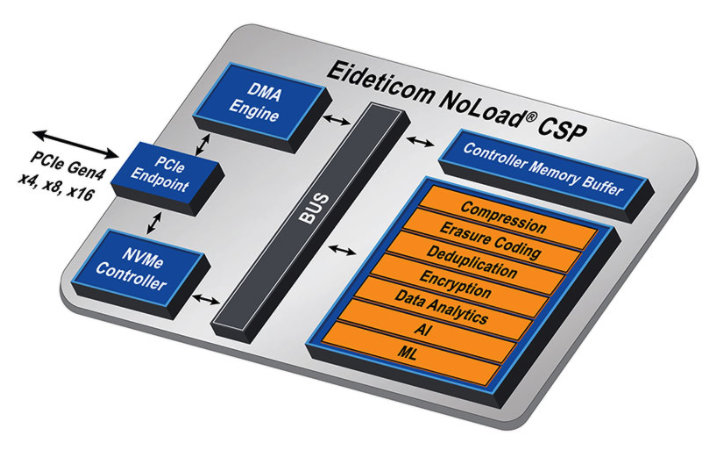
Imagen 6: funciones de hardware en la estructura NoLoad IP de Eideticom (fuente: BittWare).
La estructura NoLoad IP de Eideticom está compuesta de una pila de software «plug and play» (completa e integrada) basada en el módulo U.2 de BittWare como solución preconfigurada. Contiene un conjunto de servicios de almacenamiento computacional (CSS) acelerados por hardware (en naranja en la imagen 6).
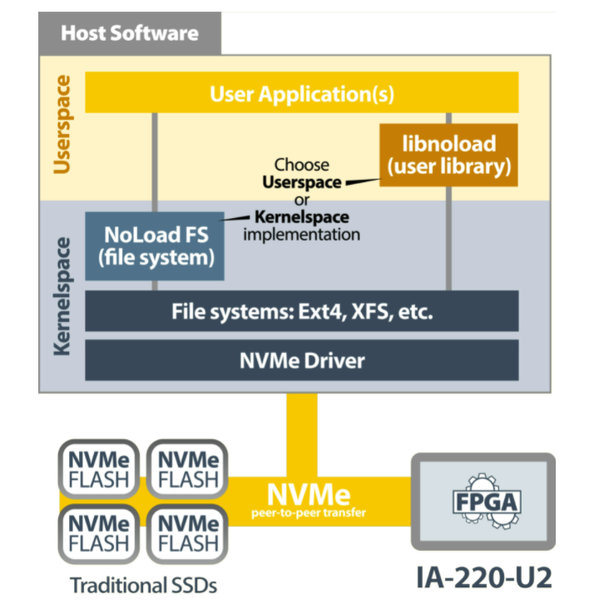
Imagen 7: pila de software NoLoad IP de Eideticom (fuente: BittWare).
Entre los componentes del software NoLoad IP (imagen 7) hay un sistema de archivos en pila en kernel y un controlador NVMe que utiliza los CSS NoLoad y el espacio de usuario para aplicaciones Libnoload.
Con la solución NoLoad de Eideticom (independiente de las CPU), la descarga en la CPU puede llegar a multiplicar por 40 la calidad del servicio, además de reducir el coste de propiedad general y los atributos de baja potencia.
Transfiera las tareas de computación intensiva y acelere el rendimiento
La implantación de una arquitectura de almacenamiento computacional con NVMe aporta grandes ventajas de rendimiento y eficacia energética en el procesamiento de grandes volúmenes de datos. Esta estrategia reduce la necesidad de pasar datos de almacenamiento a la CPU (y al revés), ya que lleva las tareas de alta computación a un procesador FPGA para el almacenamiento computacional. Los datos se guardan en grupos de almacenaje flash NAND NVMe cerca del lugar del procesamiento, lo que reduce la necesidad de ancho de banda, rebaja la latencia y mejora el ahorro energético.
www.mouser.com
